Playing Wordle with the command-line
Tuesday 04 January, 2022 at 9.09am
I hated when the family made me play Scrabble. I was only ever good at the numbers part of Countdown. And now I am also frustrated by the new word game Wordle that has been showing up in my twitter steam over the past couple of weeks.
The problem is I forget words all the time, even between starting a sentence and the point in the sentence I was going to use the word. I know the words, and it's not like I don't understand them when they are used at me. But I can't access them sometimes, even having a subset of letters doesn't make it any easier. And seeing jumbled letters seems to make this worse, not better. Consequently, any game that's about being able to come up with words leaves me cold.
I failed my first three attempts at Wordle, and got stuck on the fourth attempt because I couldn't think of any words that matched the constraints before me. So I cheated, and found there was one exact match, and it was just so obvious once I realised I could use a letter twice. But all questions are easy when you know the answer.
Anyway, if you're anything like me, and have access to fairly standard Unix command-line tools, here's how you can play along too, even if you just can't words.
Prepare the first guess
To start with, we can find words in the file /usr/share/dict/words, which
contains a pretty comprehensive list of … well, words. Let's find those that
are only five letters.
grep '^.....$' /usr/share/dict/words
Grep is the command-line tool for finding patterns using a limited amount of
regular expressions. The caret (^) marker restricts the search to the
start of the line, the dollar ($) end of the line, and dot (.) means "any
character". So this says "print all lines that have five of any character".
But let's restrict this a little. I don't know but I suspect proper nouns
aren't likely to be used in Wordle.
grep '^[a-z]....$' /usr/share/dict/words
This replaces the first dot with a bracket expression [a-z] which means a
range, "any character between a and z". This will exclude any word starting
with a capital letter.
Now let's remove words with duplicated letters. To start, we need to break the word into separate letters.
echo -n boost | sed 's/\(.\)/\1\n/g'
This gives us the individual letters on separate lines. The sed command is a
"stream editor", and the argument 's/…/…/' does search-and-replace. The
search pattern can also use regular expressions. In this case the
any-character match is captured for use in the replacement by surrounding it
with parens ((.)); to be treated as special characters and not literal
parens they need to be escaped, hence the backslashes before them. The
replacement (\1\n) means "the first capture, and a newline". The final part
(g) is a flag meaning to repeat the match until no more are found, rather
than stopping after the first which is the default behaviour.
We can now remove duplicates using sort's uniqueness flag:
echo -n boost | sed 's/\(.\)/\1\n/g' | sort -u
This shows the letter o once, instead of twice. Now, by counting the number
of lines and testing that it is still five, we know if the word has five
distinct letters. Wrap that up into a loop, and we can check all of the
five-letter words.
for word in $(grep '^[a-z]....$' /usr/share/dict/words); do
letters=$(
echo -n $word \
| sed 's/\(.\)/\1\n/g' \
| sort -u \
| wc -l
)
[ $letters = 5 ] && echo $word
done > initial-wordles.txt
Using for word in ...; do ... done we loop over the words we found
previously, putting each word in a variable helpfully called word. Then we
set the value of a variable letters to the count of unique letters. Only if
it is 5 do we output the word. And by redirecting the output to a file, we
can capture this processing for future use.
On my 2015 iMac, processing this list takes slightly less than a minute. Yes, you could process the words much faster in an actual programming environment, but it would take just as long to write the program as it would to compose and run the shell commands.
Now we can make a first guess.
% shuf -n1 initial-wordles.txt
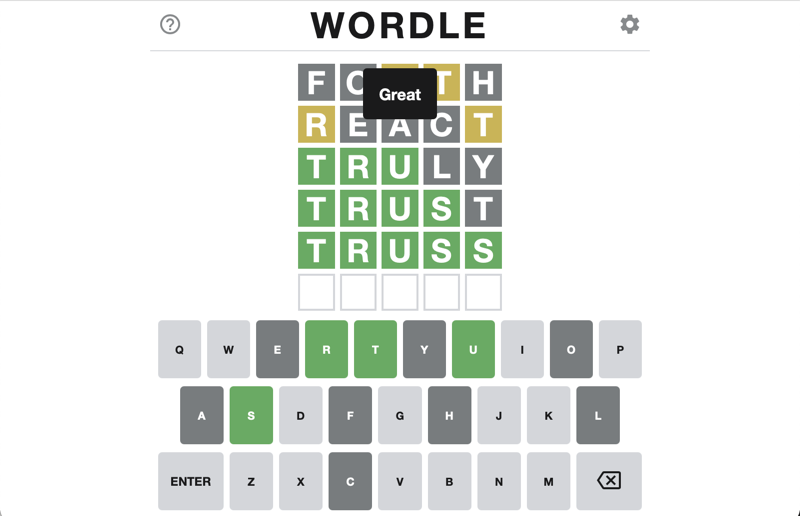
forth
shuf shuffles the lines of the initial guesses file, and -n says to then
show only the first n lines, in this case one. We get "forth", and use it.
The R and the T are in the word, but are both in the wrong place. The other
letters are not in the word.
% grep '^[a-z]....$' /usr/share/dict/words \
| grep -v '[foh]' | wc -l
Using all of the five-letter words again, we filter out (grep -v means
"invert match", so only the lines that do not match are output) any words
that contain the letters F, O, or H. I use wc -l on the end to get an idea
of how many matches there are. 4,666 words out of an initial 8,497, so we've
eliminated half the possibilities already. Now check for those that have an R
and a T.
% grep '^[a-z]....$' /usr/share/dict/words \
| grep -v '[foh]' | grep r | grep t
We grep for both individually because each line has to contain both. Now we're at 399 matches. But we also know where the R and the T aren't in the word, and can incorporate that too.
% grep '^[a-z]....$' /usr/share/dict/words \
| grep -v '[foh]' | grep r | grep t \
| grep '..[^r][^t].'
Using caret (^) at the start of the bracket expression negates it, so this new line matches any-character any-character not-an-r not-a-t any-character. Now we're at 275 matches. Let's pick one.
% grep '^[a-z]....$' /usr/share/dict/words \
| grep -v '[foh]' | grep r | grep t \
| grep '..[^r][^t].' \
| shuf -n1
react
Once again, the R and the T are in the wrong place, and the other letters are not found. Adding this information to our restrictions narrows things down considerably to just 16 matches.
% grep '^[a-z]....$' /usr/share/dict/words \
| grep -v '[aecfoh]' | grep r | grep t \
| grep '[^r].[^r][^t][^t]'
butyr
stirk
stirp
sturk
tikur
trill
trink
tripy
trubu
trull
truly
trump
trunk
truss
twirk
twirl
Note: It's worth noting at this point that some words in the Unix "dictionary" aren't words recognised by Wordle, such as the first match "butyr". You could always capture the list of five-letters words to a file, and edit out those that aren't recognised as you come across them.
I pick one myself: "truly". The first three letters match! And although I can now match the pattern in my head, for completeness let's run it once last time adding L and Y to the not-in-the-word filter, and putting T, R, and U as exact matches.
% grep '^[a-z]....$' /usr/share/dict/words \
| grep -v '[aecflohy]' | grep r | grep t \
| grep 'tru..'
trubu
trump
trunk
truss
trust
Of these, I first pick "trust", dagnabbit. Then finally the correct word "truss".